Data
As part of this BigData Cup challenge, we have released a Synthetic Vehicle Orientation (Synthetic VO) dataset containing bounding box annotations of vehicles with their class and orientation simultaneously. The dataset is publicly available at our GitHub repository or can also be downloaded from below: https://github.com/sekilab/VehicleOrientationDataset.
There are three types of data sets:
- Training (train-1 and train-2) (Synthetic images) [ Download (train-1) , Download (train-2) ]
- Test dataset 1 (test-1) (Real-world images) [ Download (test-1) ]
- Test dataset 2 (test-2) (Real-world images) [ Download (test-2) ]
The training dataset contains only synthetic images, and the test dataset (test-1 and test-2) contains eal-world vehicle images. As part of this competition, participants can use synthetic images from driving simulators or video games as the training dataset. You may refer to the following papers to understand more about the evaluation dataset from real-world.
- Kumar, A., Kashiyama, T., Maeda, H., Omata, H., & Sekimoto, Y. (2022, October). Citywide reconstruction of traffic flow using the vehicle-mounted moving camera in the CARLA driving simulator. In 2022 IEEE 25th International Conference on Intelligent Transportation Systems (ITSC) (pp. 2292-2299). IEEE.
- Kumar, A., Kashiyama, T., Maeda, H.,, Omata, H., & Sekimoto, Y. (2022). Real-time citywide reconstruction of traffic flow from moving cameras on lightweight edge devices ISPRS Journal of Photogrammetry and Remote Sensing, 192, 115-129. IEEE.
- Kumar, A., Kashiyama, T., Maeda, H., & Sekimoto, Y. (2021, December). Citywide reconstruction of cross-sectional traffic flow from moving camera videos. In 2021 IEEE International Conference on Big Data (Big Data) (pp. 1670-1678). IEEE.
| Vehicle class | Number of annotations (train-1 and train-2) |
|---|---|
| car_front | 42,273 |
| car_back | 35,017 |
| car_side | 13,131 |
| truck_front | 1,995 |
| truck_back | 2,667 |
| truck_side | 1,220 |
| motorcycle_front | 770 |
| motorcycle_back | 1,476 |
| motorcycle_side | 2,614 |
| cycle_front | 498 |
| cycle_back | 1,284 |
| cycle_side | 1,881 |
The number of annotations per class in the Synthetic VO dataset is imbalanced and follows a long-tail distribution. Thus, for a fair assessment, we will consider weighted mAP as the metric for evaluation, where we will give weights to each class based on its dominance in the test dataset provided by us, as shown below:
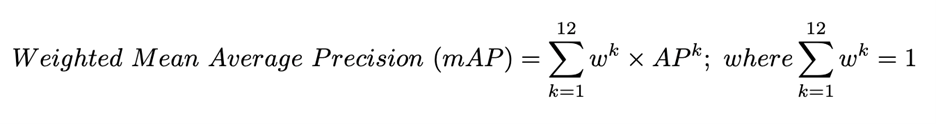
Ranking will be decided based on the value of the weighted mAP. Submissions will be ranked solely based on the weighted mAP on the test data sets. The submission with the highest weighted mAP will be ranked as the winner.